随着业务发展需要,数据量的逐步提升,需要用到Hadoop来处理一些数据,所以搭建一个Hadoop集群,搭建Hadoop集群需要多台主机,但是由于资源有限,所以刚好可以利用近些年比较火的docker来搭建,用docker搭建也有一个好处,就是一次构建多节点重复利用。在上服务器之前,现在自己的电脑里用虚拟机模拟一下,顺便可以做个记录,把可能遇到的坑先趟过去(谁叫我笔记本16G内存呢)。
第一步、安装Centos,部署docker
先从Centos官网载一个最小版的Centos7镜像,用VMWare安装,由于是最小版镜像所以装完之后有很多组件需要手动yum安装,(什么?为什么不装完全版的?我要是有几台刀片我也装啊!)
完成之后的第一步当然是换yum源:
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
安装完之后记得 yum makecache一下。由于是Minimal版,连最基本的网络工具都没有,所以全都开始手动安装:
yum install -y wget
yum install -y gcc
安装基本工具之后就是安装docker,docker安装很简单直接yum install -y docker,docker基本配置和使用就不再赘述了,docker的镜像本身下载很慢的,所以这里我用的是daocloud的加速器,那下载速度杠杠的!但是不知道daocloud最近怎么了,curl生成的加速器是有问题的,配置了之后docker启动不了,看了日志发现是他们修改的etc/docker/daemon.json有问题,里面多了一个逗号,把逗号去了就行。 接下来就是启动docker
systemctl start docker
没毛病,直接启动成功,接卸来下载镜像
docker pull daocloud.io/centos:6
为什么不用centos7而是用6,这个问题就比较搞笑了,刚开始用的就是7的镜像但是有个很严重的BUG就是systemd无法使用,也就是说容器内的服务是无法用systemctl管理的,网上也有解决方法,但是都不好使!所以退而求其次用centos6就行。镜像拉取完成之后启动镜像:
docker run -it -h master --name master daocloud.io/library/centos:6 /bin/bash
ok~!镜像启动成功,控制台会直接进入镜像内的控制台,如果想退回宿主机控制台直接ctrl+p ctrl+q可以从容器返回宿主机,再想回来直接docker attach 【容器名称或ID】。
第二步、制作Hadoop镜像
进入容器控制台,开始搭建Hadoop,在搭建之前一样要先把基础工具给装了,Hadoop是JAVA写的所以JDK先给装上:
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
mkdir /usr/java
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/java
修改环境变量
vim /etc/profile
#在最下方加入JAVA配置
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
export JAVA_HOME=/usr/java/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#source一下
source /etc/profile
安装gcc,vim,lrzsz和ssh
yum install -y gcc
yum install -y vim
yum install -y lrzsz
yum -y install openssh-server
yum -y install openssh-clients
配置ssh免密登录
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
关闭烦人sellinux:
setenforce 0
启动ssh
service sshd start
测试一下
ssh master
如果没什么问题就代表一些准备就绪。
完成之后开始下载Hadoop镜像:
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
mkdir /usr/local/hadoop
tar -zxvf hadoop-2.8.0.tar.gz -C /usr/local/hadoop
配置环境变量
vim /etc/profile
#在最下方加入Hadoop配置
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin
修改Hadoop的配置文件,进入Hadoop的目录
cd /usr/local/hadoop/hadoop-2.8.0/etc/hadoop/
在hadoop-env.sh 和 yarn-env.sh 在开头添加JAVA环境变量JAVA_HOME
修改hadoop core-site.xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/tsk/hadoop-2.8.0/tmp</value>
</property>
</configuration>
修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/tsk/hadoop-2.8.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/tsk/hadoop-2.8.0/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
</configuration>
由于我准备配置三个salve节点所以在slaves文件中添加
slave1
slave2
slave3
完成之后尝试一下
ldd /usr/local/hadoop/hadoop-2.8.0/lib/native/libhadoop.so.1.0.0
这时提示GLIBC_2.14 required,centos6的源最高到2.12,这里需要2.14,所以只能手动make安装
wget http://ftp.gnu.org/gnu/glibc/glibc-2.14.tar.gz
tar zxvf glibc-2.14.tar.gz
cd glibc-2.14
mkdir build
cd build
../configure --prefix=/usr/local/glibc-2.14
make
make install
ln -sf /usr/local/glibc-2.14/lib/libc-2.14.so /lib64/libc.so.6
完成之后再ldd就没有问题了!接下来就是构建上面做的所有操作,将其变成一个镜像以便复用,先Ctrl+p和Ctrl+q返回宿主机控制台然后输入命令:
docker commit master tsk/hadoop
等一会之后会发现镜像只做完成docker images一下就能看到自己只做的镜像了。
第三步、启动镜像
先配置docker的网络,给每台机器配置host
docker inspect --format='{{.NetworkSettings.IPAddress}}' master
接下来逐个启动镜像:
docker stop master
docker rm master
docker run -it -p 50070:50070 -p 19888:19888 -p 8088:8088 -h master --name master tsk/hadoop /bin/bash
docker run -it -h slave1 --name slave1 tsk/hadoop /bin/bash
docker run -it -h slave2 --name slave2 tsk/hadoop /bin/bash
docker run -it -h slave3 --name slave3 tsk/hadoop /bin/bash
然后attach到每个节点上面source一下配置hosts,启动sshd,完成之后开始准备启动Hadoop
hadoop namenode -format
/usr/local/hadoop/hadoop-2.8.0/sbin/start-all.sh
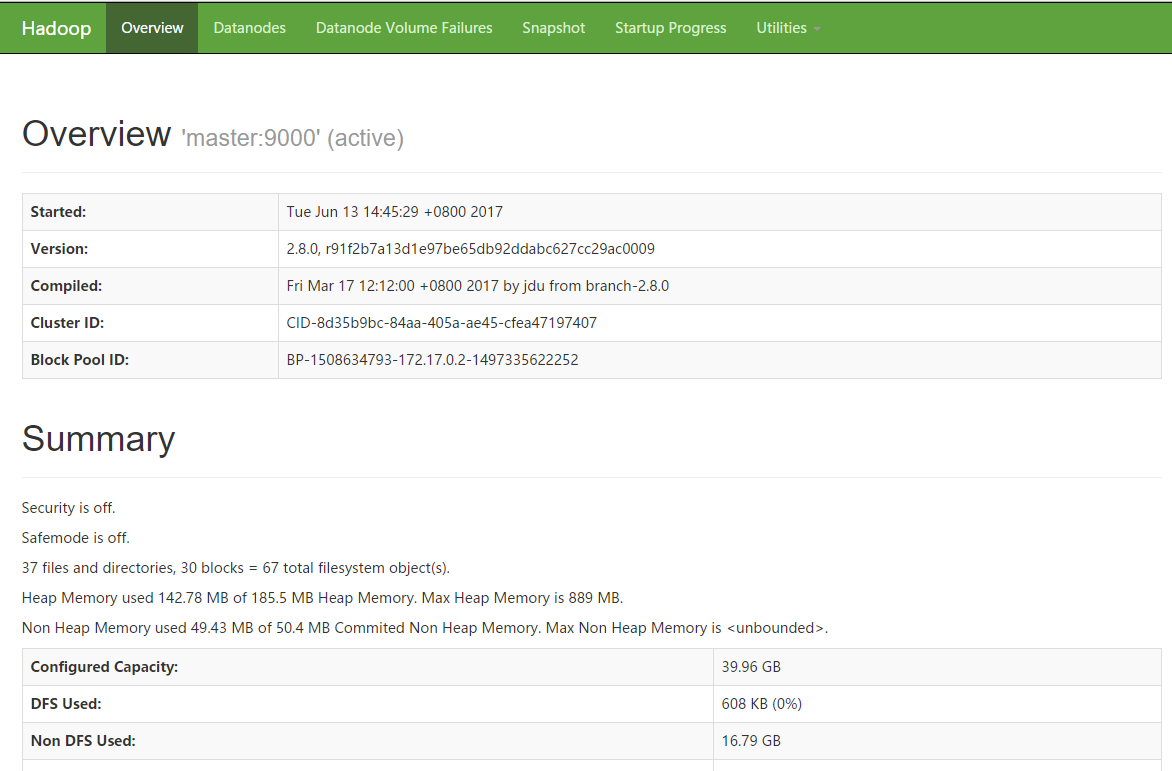
最后要做的事情就是等待~等待~等待~~~~!直到全部启动完成!完成之后用浏览器访问虚拟机IP地址:50070,如果没有任何问题的话你就可以看到如下画面,至此Hadoop集群搭建成功!