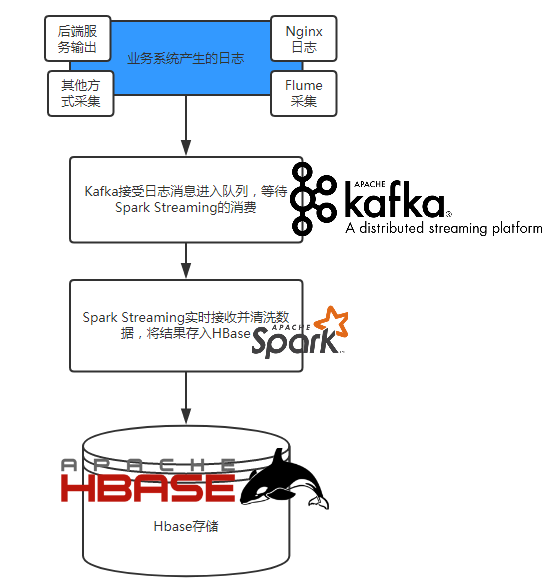
一、前言
一个好的产品少不了一个好的产品经理的策划与设计,外界普遍认为产品经理也隶属于技术工种,但其实不是,产品经理在我看来属于文艺圈,设计一套产品对他们来说是创作,可以天马星空,可以不受任何束缚尽情创作,所以产品经理普遍是不知道他们设计的产品是如何实现的,这就是为什么我们经常听到或者看到网上产品经理和技术开发之间的各种争斗段子。产品经理不懂技术在创作层面上来说是必要的,反之一个好的技术是绝对设计不出一款好的产品的,如果让一个人即做开发又做产品。。。。。。我真的很难想象产品出来是啥样子的。。。。。。
那么问题来了,产品经理到底要不要懂技术呢?答案是了解就好,不要深入也不能完全不懂!为什么?打个比方,我们设计一个摩天大楼,这个大楼的设计者可以完全不用考虑各种物理定律天马行空,漂浮在半空中的天空之城都没问题,但是这种大楼至少在他活着的时候是不会竣工的甚至都不会动工,真正好的设计至少他得知道楼为什么不能漂浮在半空中,怎么设计这个楼才不会倒塌等等。相应的,产品经理所要了解的东西也远不止如何天马行空如何让最终用户眼前一亮。恰巧,我认识一个产品经理他就完全不懂技术,最近发现了自己至少得了解一下产品是如何实现的,所以在网上看了半天,还是云里雾里,看了还不如不看越看越懵逼。
以上是这篇文章的前提条件,为了不让我认识的这位产品小达人更加迷茫,我决定给他写一篇干货,介绍一下他的产品到底是如何落地的。